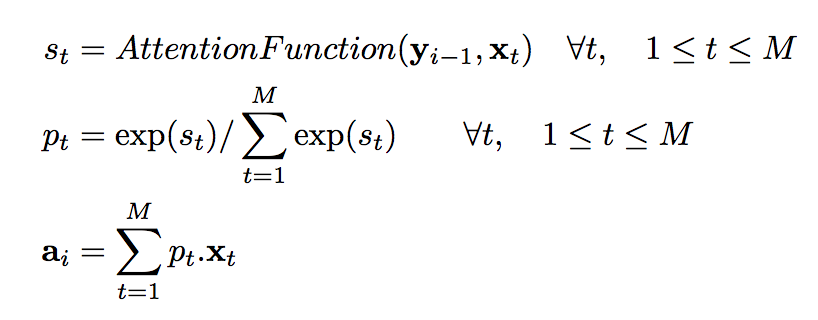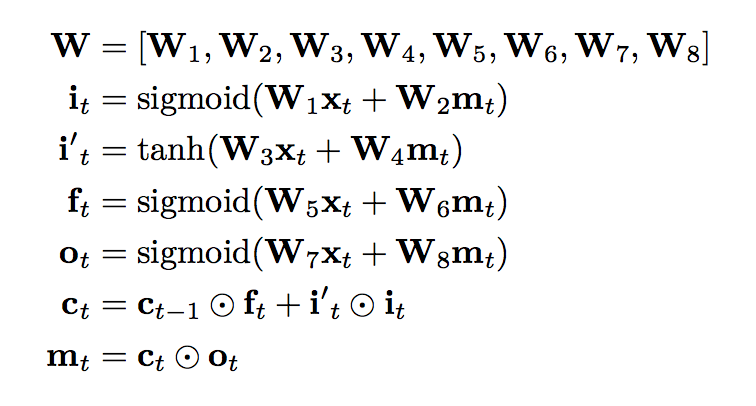Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
This is google’s newest machine translation system based on deep learining(NMT) disclosure in detail. It’s a weights more on the techniques/tricks used to build the production enviroment system.
Three inherent weaknesses of Neural Machine Translation GNMT tends to solve:
its slower training and inference speed
ineffectiveness in dealing with rare words
sometimes failure to translate all words in the source sentence
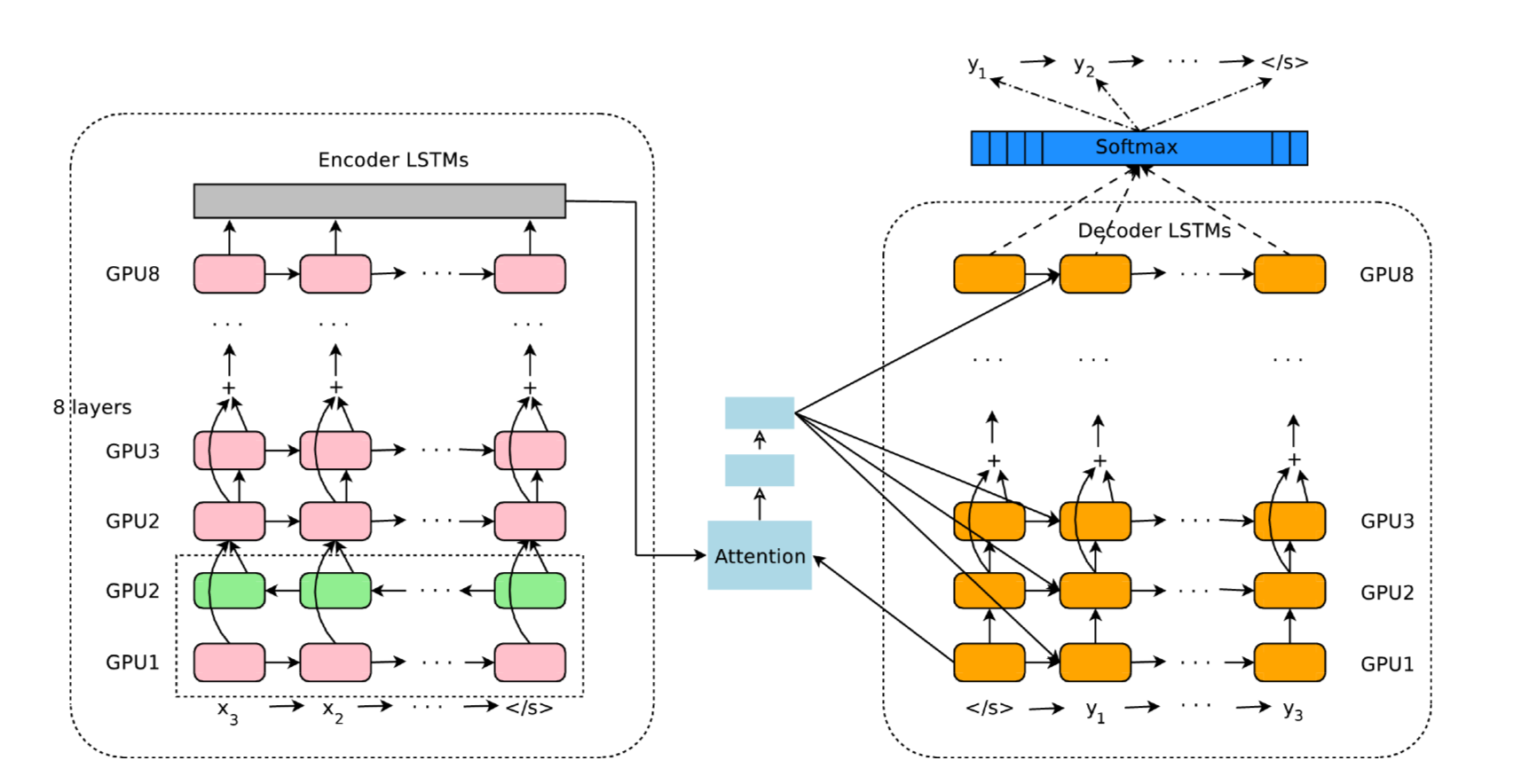
Model
8 hidden layer LSTM RNNs (in encoder network and decoder network)
residual connections
attention (attention network)
deep stacked LSTM
Since each additional layer reduced perplexity by nearly 10% showed by paper[1], this model stacked 8 layers to encoder and decoder,
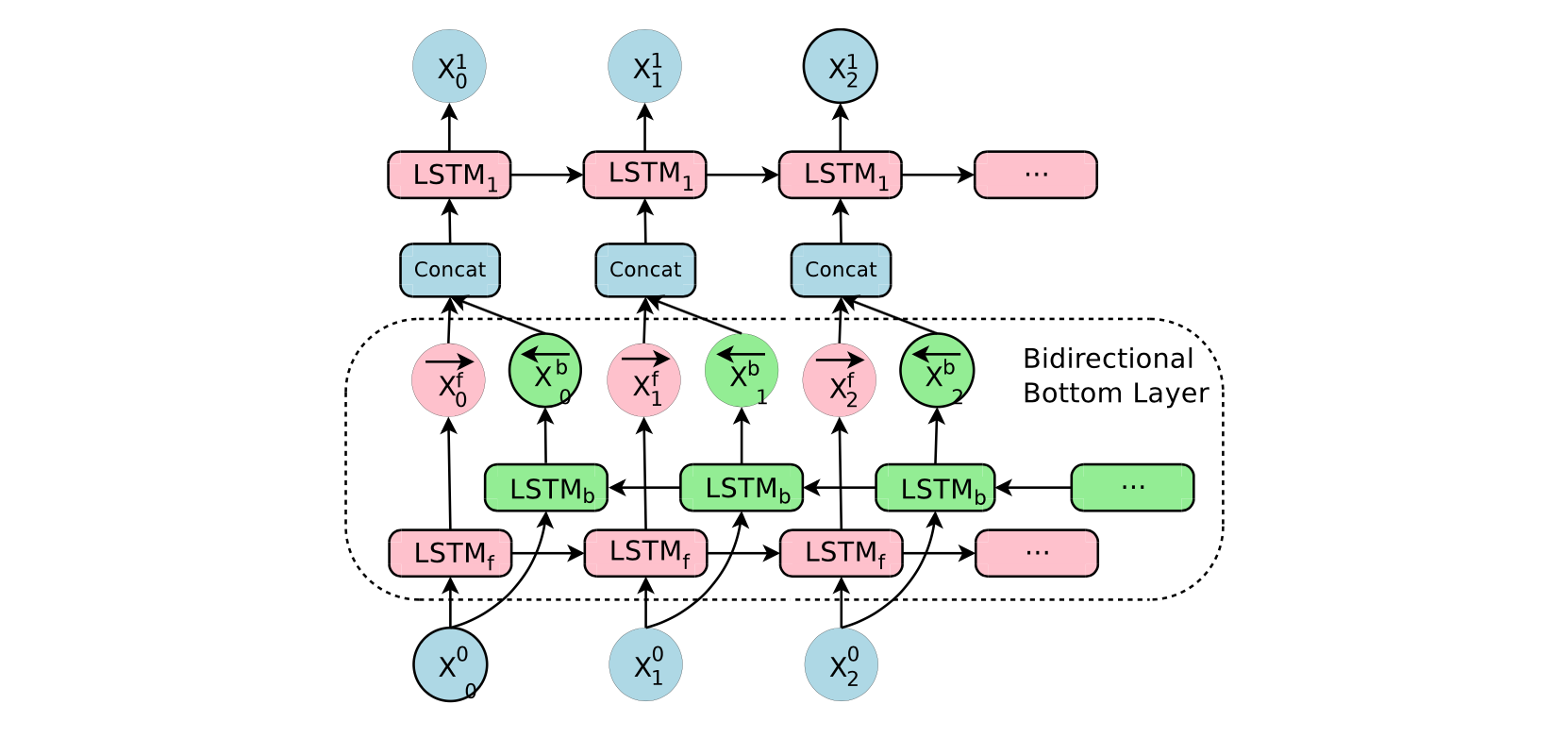
with first encoder layer a bidirectional layer to have the best possible context at each point in the encoder network,which is also used in [2]. To allow for maximum possible parallelization during computation, bi-directional connections are only used for the bottom encoder layer – all other encoder layers are uni-directional.
attenion network
Attention function is learned through a 1 hidden layer neural network.
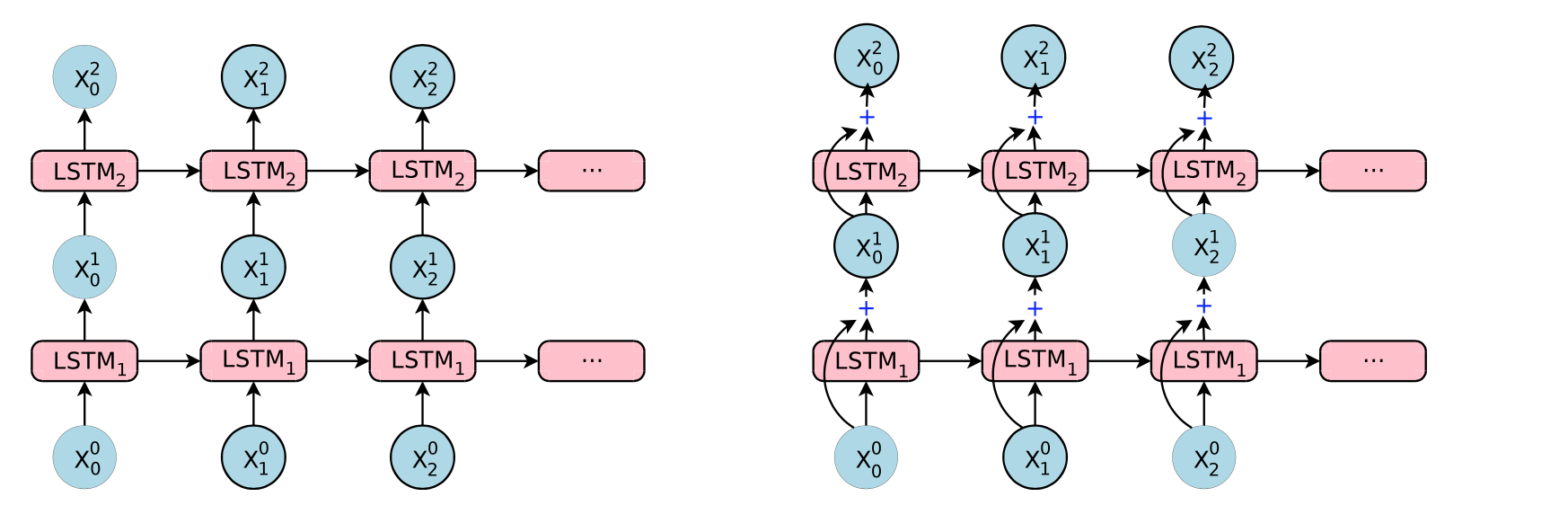
residual connections
Simple stacked LSTM layers work well up to 4 layers, barely with 6 layers, and very poorly beyond 8 layers. Thanks to [3], deeper stack lstm is working.
Other techniques
sub-word units(wordpieces)
beam search
wordpieces
This technique is introduced when developed to solve a Japanese/Korean segmentation problem for the Google speech recognition system in [4]. Wordpieces model is a data-driven model and guaranteed to generate a deterministic segmentation for any possible sequence of characters. It is similar to the method used in [5] to deal with rare words in Neural Machine Translation.
an example of wordpiece:
• Word: Jet makers feud over seat width with big orders at stake
• wordpieces: _J et _makers _fe ud _over _seat _width _with _big _orders _at _stake
This is just introduce higher dimension to learn the subtlety of morphology.
decoder beam search
Typically keep 8-12 hypotheses but we find that using fewer (4 or 2) has only slight negative effects on BLEU scores.
Refinements to the pure max-probability based beam search algorithm:
a coverage penalty [6]
length normalization
Without some form of length-normalization regular beam search will favor shorter results over longer ones on average since a negative log-probability is added at each step, yielding lower (more negative) scores for longer sentences.
tricks
low precision at inference
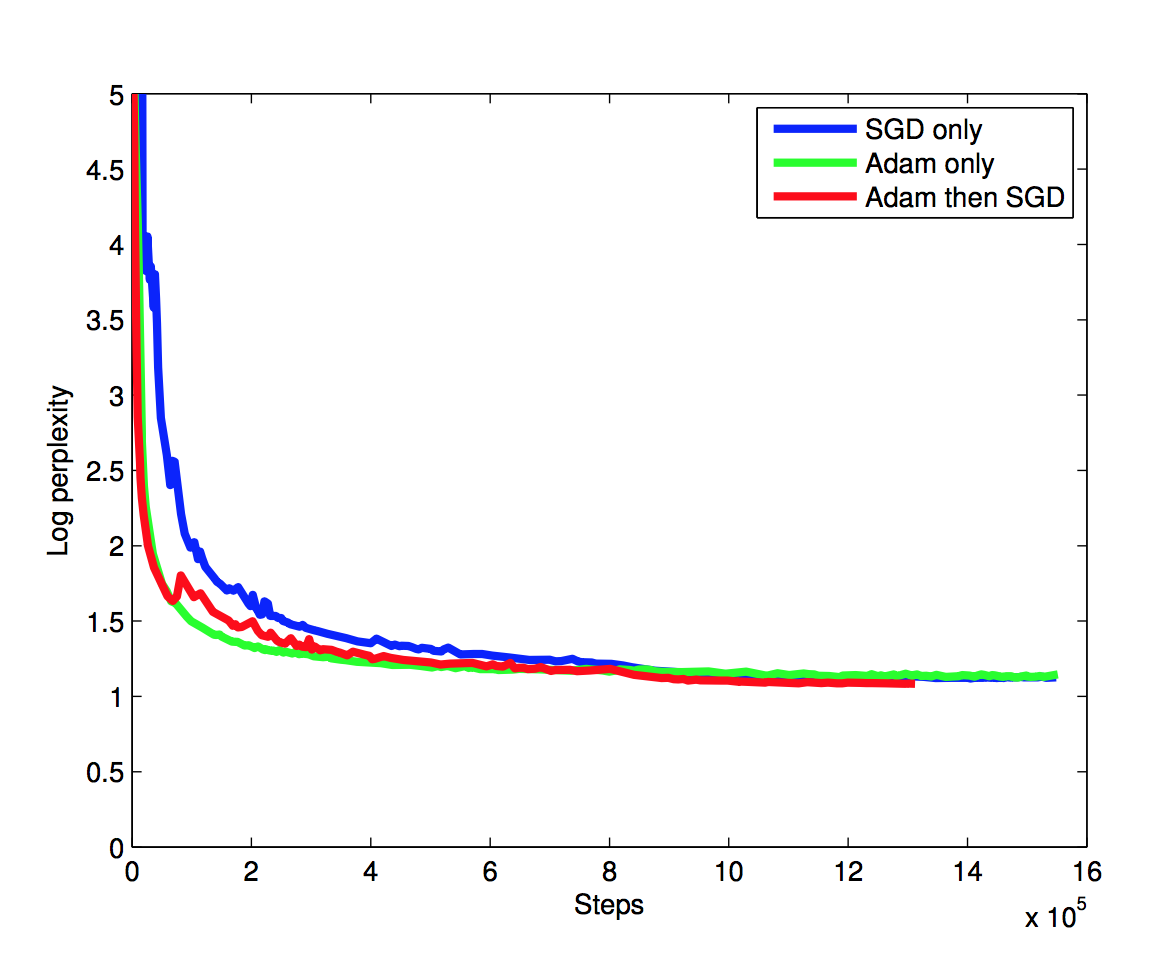
constrains during training:
train first with adam then standard sgd
Reference
[1]Sutskever, I., Vinyals, O., and Le, Q. V. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems (2014), pp. 3104–3112.
[2]Bahdanau, D., Cho, K., and Bengio, Y. Neural machine translation by jointly learning to align and translate. In International Conference on Learning Representations (2015).
[3]Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” Advances in neural information processing systems. 2015.
[4]Schuster, M., and Nakajima, K. Japanese and Korean voice search. 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (2012).
[5]Sennrich, R., Haddow, B., and Birch, A. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (2016).
[6]Tu, Z., Lu, Z., Liu, Y., Liu, X., and Li, H. Coverage-based neural machine translation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (2016).
I see the trend of Neural network approaching the network in network in the future. As some fully end-to-end trained network can be fine tuned at the connection of the ‘parent’ network, reaching a small well functioning part of the ‘brain’.
These ideas are coming from GoogLeNet, fast and faster -RCNN.
Recently I am struggling about which build tool to use that can do once for all or at least most of the language that I use to build
my project. And I found the following one as a start:
Back in my youth, programs used to come as listings in magazines that you copied into the ZX81’s BASIC editor and then ran. How times have changed. Building software has become more complex as the underlying runtimes and platforms have evolved. As a result of that, we have seen an evolution in build tools. I started my working life using Make (for both C++ and Java), before progressing onto Apache Ant and Apache Maven 2. For a brief interlude I even worked with CMake, which I found to be one of the more challenging tools to learn and understand.
Gradle is a recent entrant to the field, and my current build tool of choice. What lifts it above the more established tools, Ant and Maven? This is a question that anyone involved in building Java software in particular should be asking themselves.
Let’s go back to basics and ask ourselves what we want from a software build. As an example, consider the process of compiling a Java application. You could use the javac command directly, but then you would have to ensure that all the appropriate source files were specified on the command. And don’t forget all the JARs you’d have to include in the classpath. Imagine specifying that command line each time you wanted to recompile the source files. It’s ridiculously time consuming and error prone, hence why any sane developer or team uses a build tool to automate the process. And this is the key foundation of building software: automating the steps required to go from the inputs (typically source files) to the outputs (packaged applications, deployed web applications, etc.).
Automation provides a couple of major benefits:
Reliability – you’re eliminating many potential sources of human error
Time saving – fewer manual steps means less time wasted
Another consideration is reproducibility. In other words, given a fixed set of inputs, we want the outputs to always be the same. If a build is not reproducible, you won’t be able to guarantee that you’re building the same binaries that you gave to a client a year or two back. Build tools can certainly help with this by removing the human error component, but they are not sufficient on their own as you can easily make a build that is dependent on its environment.
In essence, we want a build tool that allows us to automate as much of the development and deployment process as possible. Most of us already include compilation, running unit tests, and packaging, but what about:
Creating a complete developer environment for a project from scratch
Generating a project’s documentation (possibly in multiple languages)
Running the application in a special developer mode
Running functional/integration tests that require special setup
Automatically updating source control management (SCM) information, such as tags
Stopping, deploying, and restarting server apps in different environments
A lot of these aspects are very project-specific and require customization of the build. It’s also becoming quite common to mix multiple languages and platforms into a single project, such as JavaScript for a rich browser front end and Java for the back end. How should you handle these project-specific build requirements? You might use different tools or run special scripts manually, but that kind of appraoch takes you away from the ideal of a fully automated process, weakening the benefits I talked about earlier.
Full automation is an important goal for building software, but it’s not the sole one. How much effort does it takes to set up a software build in the first place and how easy it is for an outside or new hire to understand it? You don’t want developers and build masters wasting time trying to understand how to use a highly customised build system if you don’t have to. That’s where the concept of conventions comes in: standardise those things that are common to the majority of software projects of a particular type. Think directory structure, compilation, packaging, etc. Maven hit the nail on the head when it introduced conventions to Java build.
In real life, most projects will be a mix of standard build bits and custom steps. They’ll often be mostly standard with just a few customisations. So ideally you want a tool that gives you a bunch of conventions that you can follow, but with the flexibility to both customise the standard steps and introduce your own ones. This is where I feel Gradle shines. Consider this basic build for a Java project:
It’s not very long, but this build file gives you everything you need to compile, test, and package a Java project that follows the conventions established by Maven. Anybody that knows those conventions will be able to easily navigate their way around the project and understand from the build file exactly what is specific to this project (such as the dependencies).
Now consider a scenario in which you have a build step (or task in Gradle parlance) that generates some source files that should be included in the compilation. There are two things you need to do:
Make sure the source code generation happens before the compilation
Configure the compiler to include the files in the generated source directory
This may seem intimidating at first, but Gradle gives you access to a full-featured API that makes such customizations trivial. This is all you need to add to the original build file:
It’s not the ideal approach, but it gives you an idea of what’s possible.
So where is all the stuff that implements compilation, testing, packaging etc.? You may have already guessed: the Java plugin. It contains all the relevant tasks (JavaCompile, Test) as well as the conventions that tie all those tasks together. In fact, if you don’t include the Java plugin in your build, then you don’t get any of that stuff. This is great if you want to build something else entirely, such as a user guide, or a JavaScript project. The only thing that Gradle forces you to do is model your build in terms of a graph of tasks. But that’s flexible enough to satisfy any build requirements you might have.
The inherent flexibility of Gradle combined with this concept of plugins means that Gradle can be used to build not only Java projects but also Android and C/C++ ones. You can find plugins to create executable fat JARs (Shadow plugin), create command line apps (Applicatin plugin), build documentation projects based on Asciidoctor, and more. And there’s nothing stopping you from creating your own types of conventional build.
Let’s not get carried away though. Gradle is a powerful tool that rewards time spent understanding it. It’s simple to use for simple projects, but you can easily dig yourself into a deep hole if you abuse the power given to you. That’s the trade off: you’re given the flexibility to solve your problems and shoot yourself in the foot. Be responsible.
Hopefully this post has given you some inkling of what differentiates Gradle from its competitors and how it can help you model your own non-trivial build processes. Feel free to use the comments to raise questions!