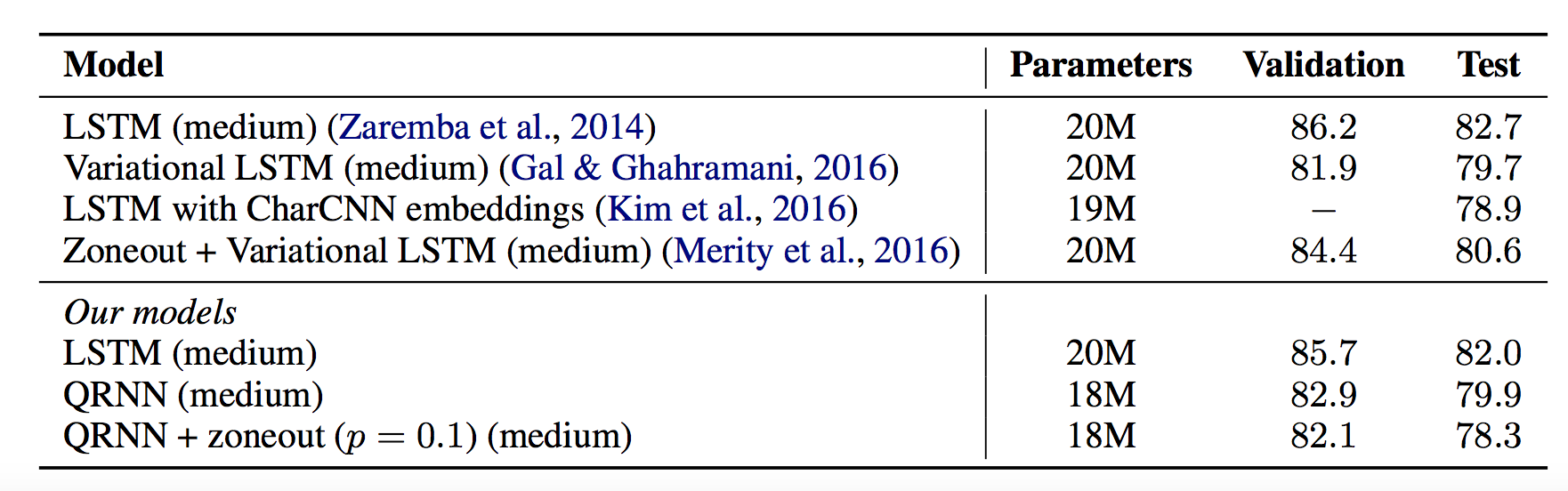
Survey on knowledge representation and reasoning based on statistical machine learning
对于知识图谱,大家的处理切入点有所差异, 多数都是基于应用的深度学习训练。见以下Tasks。
Jason等在13, 14年在google时的knowledge base体系基于embedding(entities,relations are all dense vectors) 一个理论框架下的模型(TransfE)与应用(QA, RE).
Translating Embeddings for Modeling Multi-relational Data(theory)给出了TransfE 用于学习 entities 和 relations的向量表示,他们的工作是类似energy based embedding,基本思想是三元组(e1,r,e2)构成 e1+r~=e2, 而非基于word2vec。 他的当年另外两篇文章分别细致化了关系抽取和问答系统。 值得一提的是他们的关系抽取可以对给定的两个entities正确推理出训练集中从未出现的关系。
以上框架,给出了一个较为完善的工作体系, 即学习dense vector(entities, relations), knowledge based completion(即对于训练集中没有出现的关系,能够正确合理的推断/补全), 对话(即我们的理想的应用)。
围绕着以上三点, 2014年以后有很多细致的工作在展开。 nips 2015的 workshop reasoning, attention and memory(RAM)给出了一些突破的方向. 如workshop的题目, 三元组(reason, attention, memory)是解决问题当前的核心, reason 依赖于memory,而attention 给agent 一个读取memory的合理机制。 在knowledge graph进行推理 同样依赖于这个三元组。
Reaserchers/Research Groups:
Facebook:
Jason Weston and Antoine Bordes, Sumit Chopra
Jason等 在14年在google时的一套KB体系基于embedding(entities,relations are all dense vectors) 一个理论框架下的模型(TransfE)与应用(QA, RE).
Translating Embeddings for Modeling Multi-relational Data (theory) Open Question Answering with Weakly Supervised Embedding Models (application Question Answering[QA]) reasoning simple relations within Freebase.
Connecting Language and Knowledge Bases with Embedding Models for Relation Extraction:(application relation extraction[RE])
employs not only weakly labeled text mention data, as most approaches do, but also leverages triples from the known KB. The model thus learns the plausibility of new triples by generalizing from the KB, even though this triple is not present.
weakly supervised means for each pair of entities detected in the text, all relation mentions associated with them are labeled with all the relationships connecting and in the KB, whether they are actually expressed by or not.
CMU
Read the Web
To build a never-ending machine learning system that acquires the ability to extract structured information from unstructured web pages. If successful, this will result in a knowledge base (i.e., a relational database) of structured information that mirrors the content of the Web. We call this system NELL (Never-Ending Language Learner).
Eric P. Xing group(http://www.cs.cmu.edu/~epxing/publications-2016.html)
- Harnessing Deep Neural Networks with Logic Rules (distillation method that transfers the structured information of logic rules into the weights of neural networks)
- Deep Neural Networks with Massive Learned Knowledge (Distillation model)
Stanford
NLP group
- Reasoning With Neural Tensor Networks for Knowledge Base Completion
- Learning new facts from knowledge bases with neural tensor networks and semantic word vectors
HAZY (research) -> deepdive(opensource) -> https://lattice.io/ (commercial)
The Hazy project is exploring integrating statistical processing techniques with data processing systems with the goal of making such systems easier to build, to deploy, and to maintain. Currently mainly for knowledge-base construction
we are building several applications, including systems to read large amounts of text and answer sophisticated questions (see WiscI and GeoDeepDive) and building general primitives for data analytics that are now incorporated in products from Oracle and Pivotal. Additionally, some of our ideas have helped to find Neutrinos with IceCube (see IceCube).
DeepDive, a general-purpose statistical inference system, has been released.
GOOGLE:
Google’s Knowledge Vault
constructing knowledge bases based on the web.
Microsoft:
Tasks
conversation/dialog/chat: Knowledge Graphs and Linked Big Data Resources for Conversational Understanding
recommendation: Collaborative Knowledge Base Embedding for Recommender Systems
semantics: Deep learning of knowledge graph embeddings for semantic parsing of Twitter dialogs
Datasets
- Freebase triplet relationships
- WordNet
- babi towards the goal of automatic text understanding and reasoning
MISC
-
nips-2015-reasoning-workshop important
-
Memory Networks for Language Understanding, ICML Tutorial 2016
-
Linked Data by connecting various information from different topic domains such as people, books, musics, movies and geographical locations in a unified global data space